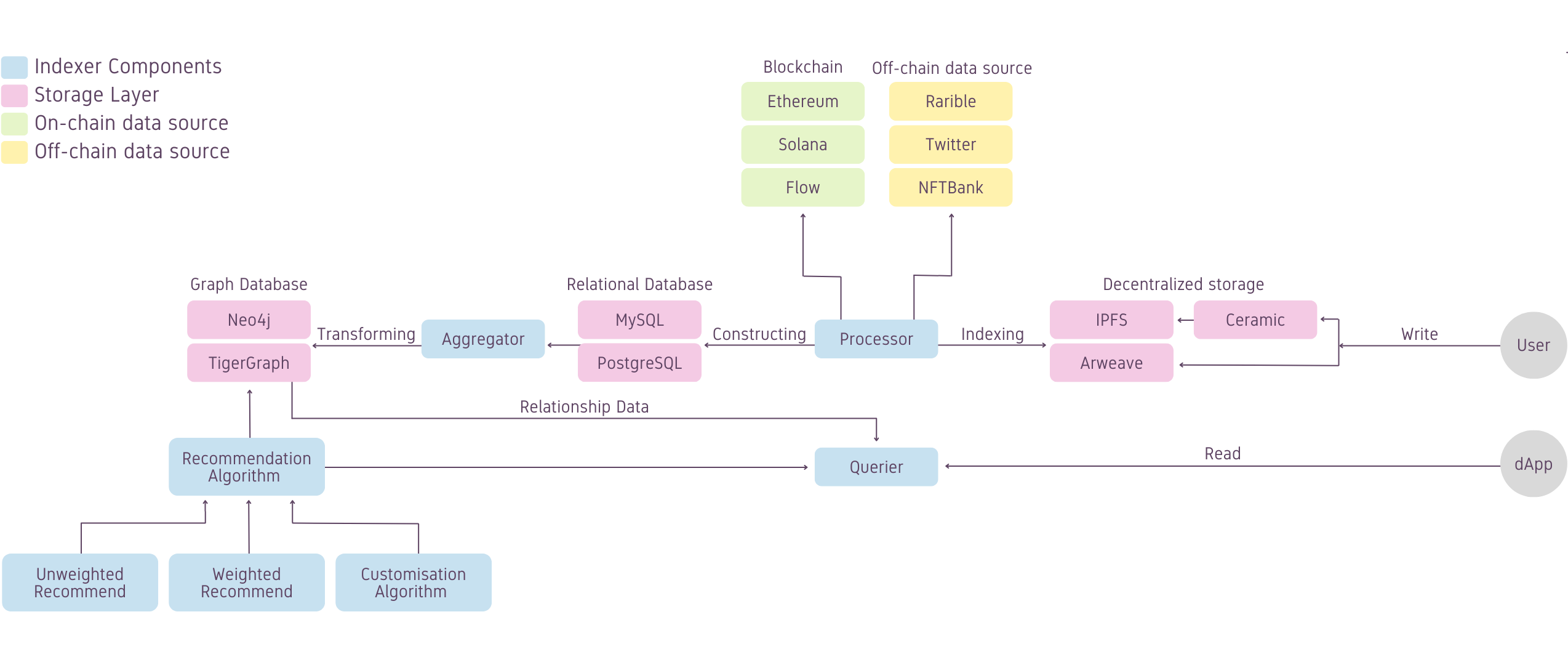
Data Indexing
There are three data sources in our indexing system: blockchains (e.g. Ethereum, Solana, BNB Chain), decentralized stores (e.g. IPFS, Arweave), and off-chain platforms (e.g. Foundation, Rarible, Twitter). Its general philosophy is to index data that could be potentially reused in various social contexts. For example, connection data on existing platforms like Foundation, POAP token for each address.
Data indexing is composed of three components: data processing, data aggregation and data querier.
Data Processor
The processor connects to different blockchain full nodes (e.g. ETH, Solana) to watch real-time contract event data and run cron jobs to regularly fetch data from off-chain social platforms (e.g. Twitter, Context, Foundation). It stores this indexed information as structured data in relational databases such as MySQL and PostgreSQL. These data are indexed for long-term persistent storage to avoid re-processing penalties.
Data Aggregator
It is difficult to query data with high degrees of separation in a social graph with a relational database and systems built on top. One way to achieve that is using continuous JOIN operations in relational databases, but this only works to a limited degree while incurring tremendous performance penalties.
The aggregator aggregates structured data from relational databases into graph representation and stores that aggregated data in graph databases such as Neo4j and DGraph. Storing data in a graph database gives developers more query capabilities and makes graph-based data analysis and recommendation possible.
Future research could introduce different aggregating schemes based on the persistent data stored in the first step of data processing. Data aggregators also need to serve the query interface. Technically, one server could fulfill the tasks of both data processor and data aggregator.
Data Querier
The Querier serves three main purposes: providing identity data, providing relationship data, and connection recommendations. It retrieves data from graph databases, gets recommendation results from the Recommender, and returns data in the way requested.
Architecture